大数据告诉你:10年漫威,到底有多少角色
在统计学领域,有些人将数据分析划分为描述性统计分析、探索性数据分析以及验证性数据分析;其中,探索性数据分析侧重于在数据之中发现新的特征,而验证性数据分析则侧重于已有假设的证实或证伪。
最近正值复联4上映,小F也发现了一个有趣的网站。主要是关于漫威人物、漫威电影的图谱。网站是基于Graph技术开发的。其实之前小F也利用了有关Graph的库实现了一波人物的关系分析。只不过分析结果比较粗糙而已~
网站是基于Graph技术开发的。
其实之前小F也利用了有关Graph的库实现了一波人物的关系分析。
只不过分析结果比较粗糙而已~
下面是网站的概况,大家可以一览。


那么人家能做出这么酷炫的关系图,我们自己能不能实现呢?
这一期就利用网站提供的数据,使用Neo4j(NOSQL图形数据库)进行实战一波。
一、获取分析
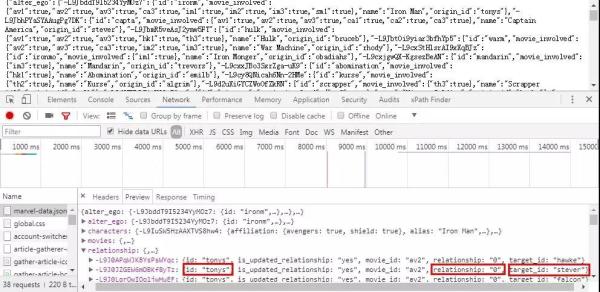
人物及人物关联信息从网站上获取,具体接口如下。

数据为json格式,分别在「characters」和「relationship」中。

这里的信息是分别指托尼·斯达克,关系「0」为朋友,斯蒂文·罗杰斯。

二、 数据获取
具体代码如下。
- headers = {
- 'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
- }
-
- url = 'https://graphics.straitstimes.com/STI/STIMEDIA/Interactives/2018/04/marvel-cinematic-universe-whos-who-interactive/data/marvel-data.json'
- response = requests.get(url=url, headers=headers)
- result = json.loads(response.text)
-
- num = 0
- names = []
- item = {0: 'friend', 1: 'enemy', 2: 'creation', 3: 'family', 4: 'work', 5: 'love'}
-
- for i in result['relationship']:
- subject = result['relationship'][i]['id']
- object = result['relationship'][i]['target_id']
-
- if subject not in names:
- names.append(subject)
- if object not in names:
- names.append(object)
-
- relation = int(result['relationship'][i]['relationship'])
- with open('relation_message.csv', 'a+') as f:
- f.write(subject + ',' + object + ',' + item[relation] + '\\n')
-
- for j in names:
- num += 1
- with open('names_message.csv', 'a+') as f:
- f.write(j + ',' + str(num) + '\\n')
-
- for k in result['characters']:
- id = result['characters'][k]['id']
- name = result['characters'][k]['name']
- status = result['characters'][k]['status']
- species = result['characters'][k]['species']
- with open('message.csv', 'a+') as f:
- f.write(id + ',' + name + ',' + status + ',' + species + '\\n')
最后成功获取数据。

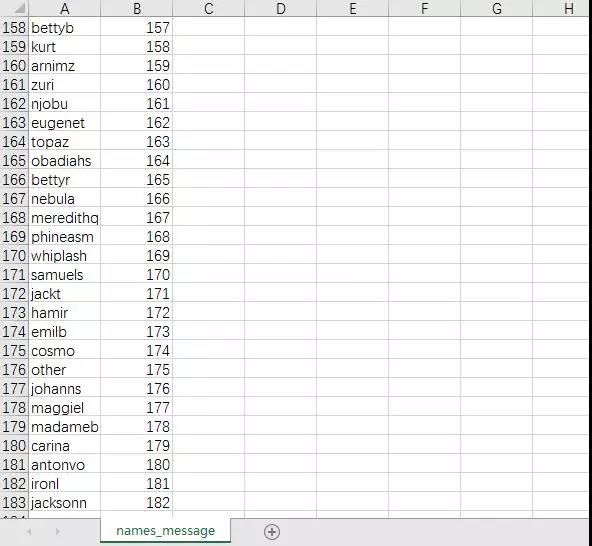
人物名为简称,共计182个人物。

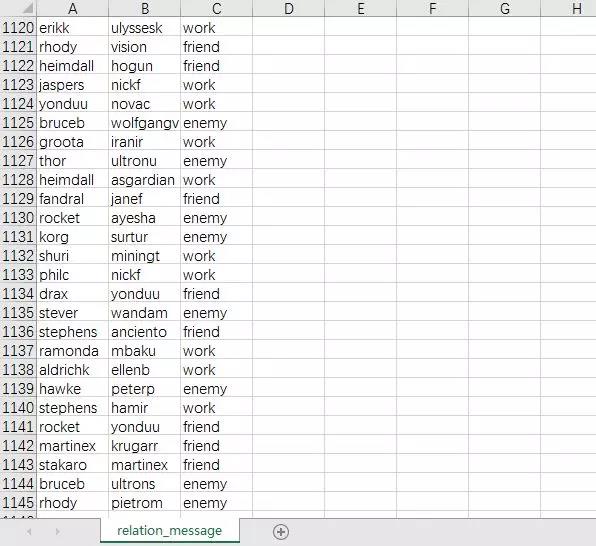
1144条人物关系数据,4大类型。
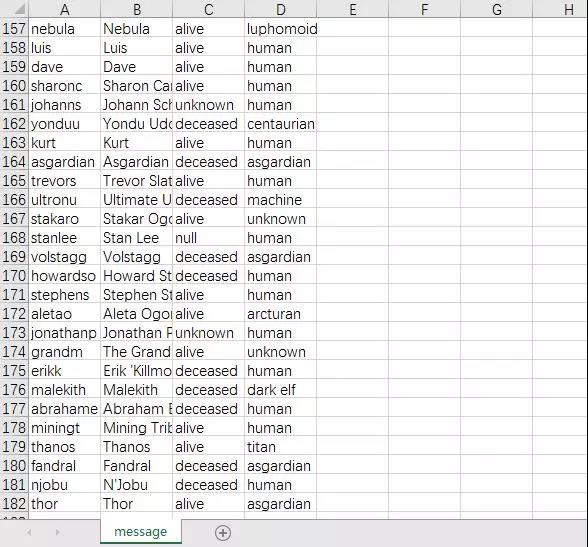
下面是182个人物的一些详情信息。

包含了人物的名字及简称,存活状态,人物属性。
三、数据可视化
下面通过Neo4j对人物关系进行可视化。
Neo4j的安装这里就不细说了,大家可以自行百度。
开启Neo4j服务后,登陆Neo4j网站,初始化界面如下。

先加载第一个文件。

具体代码如下。
- LOAD CSV WITH HEADERS FROM 'file:///names_message.csv' AS data CREATE (:people{name:data.name, id:data.id});
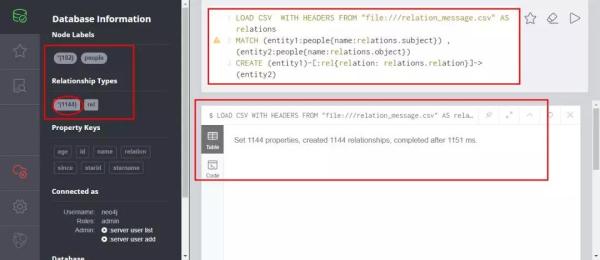
下面加载第二个文件。

具体代码如下。
- LOAD CSV WITH HEADERS FROM "file:///relation_message.csv" AS relations
- MATCH (entity1:people{name:relations.subject}) , (entity2:people{name:relations.object})
- CREATE (entity1)-[:rel{relation: relations.relation}]->(entity2)
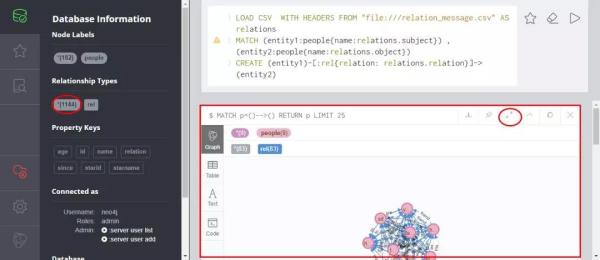
点击1144按钮处,取消限制数,再点击全屏。



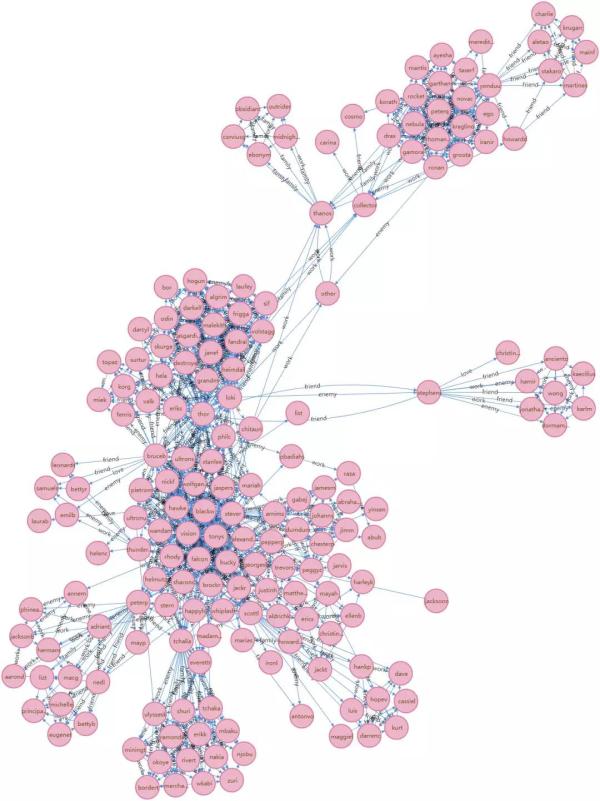
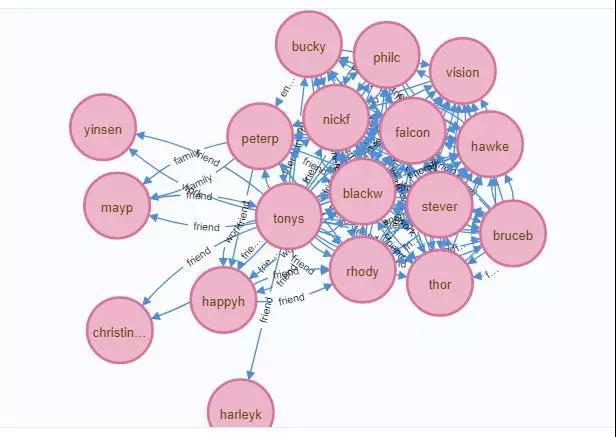
这里大致能看出来漫威的人物聚集情况。
第一大反派灭霸(thanos),原来这么孤立的。
这里由于人物太多,造成观察不便,所以对结果进行一些筛选。
比如筛选托尼·斯达克的朋友,运行下面的代码。
- match p=(n:people{name:"tonys"})-[:rel{relation:"friend"}]->() return p;
得到下图结果。

其中「thor」为「雷神」,「stever」为「美队」,「blackw」为「黑寡妇」,「vision」为「幻视」,「peterp」为「蜘蛛侠」,「bruceb」为「绿巨人」。
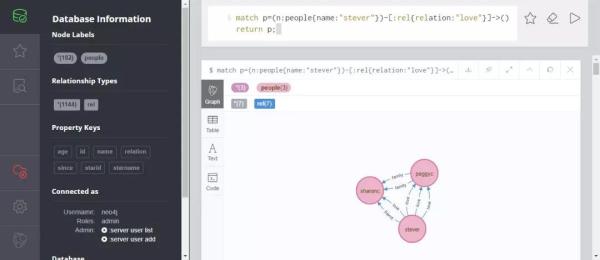
下面再来看一下美队的女友吧。

佩吉·卡特和她的侄女莎朗·卡特,据说两人样貌极为相像。
四、总结
本次只是对Neo4j的一些简单操作,后期或许会去深入了解。
此外漫威的这些人物信息,还可以玩出很多花样的。
也希望大家能去动手尝试尝试,做一枚硬核铁粉~
探索性数据分析是指为了形成值得假设的检验而对数据进行分析的一种方法,是对传统统计学假设检验手段的补充。该方法由美国著名统计学家约翰·图基(John Tukey)命名。定性数据分析又称为“定性资料分析”、“定性研究”或者“质性研究资料分析”,是指对诸如词语、照片、观察结果之类的非数值型数据(或者说资料)的分析。




 4522 人在学
4522 人在学