



利用Kettle+FineBI+MySQL构建电商运营分析报表可视化平台视频教程
 4522 人在学
4522 人在学
在众多学习中,文章也许不起眼,但是重要的下面我们就来讲解一下!!
集群环境:
1 NameNode(真实主机):
Linuxyan-Server 3.4.36-gentoo #3 SMP Mon Apr 1 14:09:12 CST 2013 x86_64 AMD Athlon(tm) X4 750K Quad Core Processor AuthenticAMD GNU/Linux
2 DataNode1(虚拟机):
Linux node1 3.5.0-23-generic #35~precise1-Ubuntu SMP Fri Jan 25 17:13:26 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
3 DataNode2(虚拟机):
Linux node2 3.5.0-23-generic #35~precise1-Ubuntu SMP Fri Jan 25 17:13:26 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
4 DataNode3(虚拟机):
Linux node3 3.5.0-23-generic #35~precise1-Ubuntu SMP Fri Jan 25 17:13:26 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
1.安装VirtualBox虚拟机
Gentoo下直接命令编译安装,或者官网下载二进制安装包直接安装:
emerge -av virtualboxoracle教程
2.虚拟机下安装Ubuntu 12.04 LTS
使用Ubuntu镜像安装完成后,然后再克隆另外两台虚拟主机(这里会遇到克隆的主机启动的时候主机名和MAC地址会是一样的,局域网会造成冲突)
主机名修改文件
/etc/hostname
MAC地址修改需要先删除文件
/etc/udev/rules.d/70-persistent-net.rules
然后在启动之前设置VirtualBox虚拟机的MAC地址
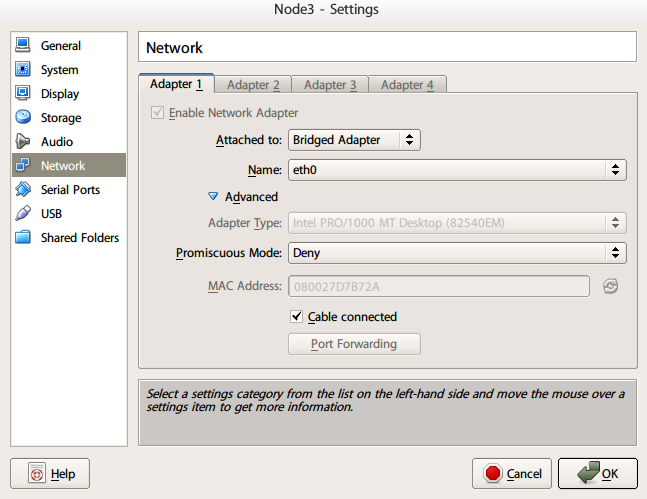
启动后会自动生成删除的文件,配置网卡的MAC地址。
为了更方便的在各主机之间共享文件,可以启动主机yan-Server的NFS,将命令加入/etc/rc.local中,让客户端自动挂载NFS目录。
删除各虚拟机的NetworkManager,手动设置静态的IP地址,例如node2主机的/etc/network/interfaces文件配置如下:
主机的基本环境设置完毕,下面是主机对应的IP地址
| 类型 | 主机名 | IP |
| NameNode | yan-Server | 192.168.137.100 |
| DataNode | node1 | 192.168.137.201 |
| DataNode | node2 | 192.168.137.202 |
| DataNode | node3 | 192.168.137.203 |
为了节省资源,可以设置虚拟机默认启动字符界面,然后通过主机的TERMINAL ssh远程登录。(SSH已经启动服务,允许远程登录,安装方法不再赘述)
设置方式是修改/etc/default/grub文件将下面的一行解除注释
GRUB_TERMINAL=consoleoracle视频教程
然后update-grub即可。
3.环境的配置
3.1配置JDK环境(之前就做好了,这里不再赘述)
3.2在官网下载Hadoop,然后解压到/opt/目录下面(这里使用的是hadoop-2.0.4-alpha)
然后进入目录/opt/hadoop-2.0.4-alpha/etc/hadoop,配置hadoop文件
修改文件hadoop-env.sh
修改文件hdfs-site.xml
修改文件mapred-site.xml
修改文件yarn-env.xml
修改文件yarn-site.xml
将配置好的Hadoop复制到各DataNode(这里DataNode的JDK配置和主机的配置是一致的,不需要再修改JDK的配置)
3.3 修改主机的/etc/hosts,将NameNode加入该文件
192.168.137.100yan-Server
192.168.137.201node1
192.168.137.202node2
192.168.137.203node3
3.4 修改各DataNode的/etc/hosts文件,也添加上述的内容
192.168.137.100yan-Server
192.168.137.201node1
192.168.137.202node2
192.168.137.203node3
3.5 配置SSH免密码登录(所有的主机都使用root用户登录)
主机上运行命令
ssh-kengen -t rsa
一路回车,然后复制.ssh/id_rsa.pub为各DataNode的root用户目录.ssh/authorized_keys文件
然后在主机上远程登录一次
ssh root@node1
首次登录可能会需要输入密码,之后就不再需要。(其他的DataNode也都远程登录一次确保可以免输入密码登录)
4.启动Hadoop
为了方便,在主机的/etc/profile配置hadoop的环境变量,如下:
4.1 格式化NameNode
hdfs namenode -format
4.2 启动全部进程
start-all.sh
VBz003.png">
在浏览器查看,地址:
http://localhost:8088/
所有数据节点DataNode正常启动。
4.3 关闭所有进程
stop-all.sh
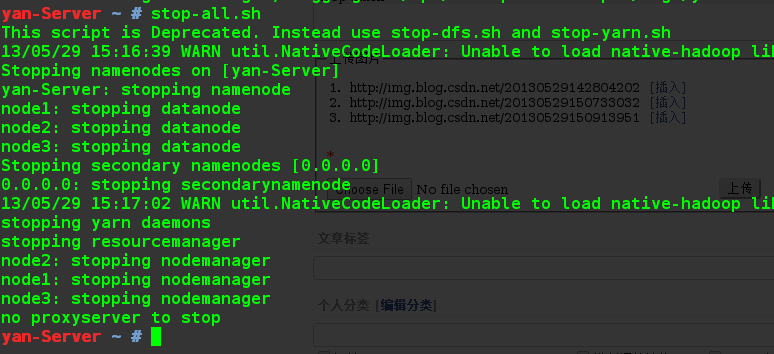
至此,Hadoop环境搭建基本结束。
更多视频课程文章的课程,可到课课家官网查看。我在等你哟!!!





