



利用Kettle+FineBI+MySQL构建电商运营分析报表可视化平台视频教程
 4663 人在学
4663 人在学
如果你使用 Python 和 pandas 进行数据分析,那么不久你就会第一次使用循环了。然而,即使是对小型数据集,使用标准循环也很费时,你很快就会意识到大型数据帧可能需要很长的时间。当我第一次等了半个多小时来执行代码时,我找到了接下来想与你共享的替代方案。
雷锋网 AI 开发者按,如果你使用 python 和 pandas 进行数据分析,那么不久你就会第一次使用循环了。然而,即使是对小型数据集,使用标准循环也很费时,你很快就会意识到大型数据帧可能需要很长的时间。当我第一次等了半个多小时来执行代码时,我找到了接下来想与你共享的替代方案。
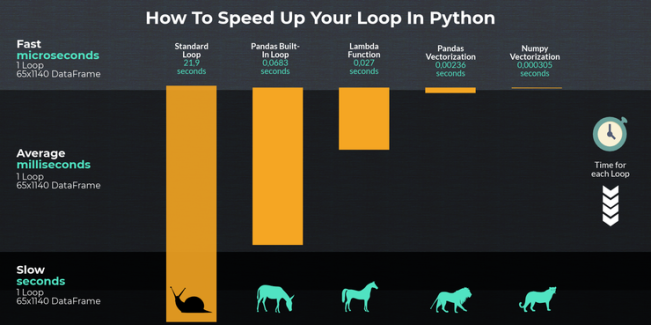
数据帧是具有行和列的 pandas 对象。如果使用循环,则将遍历整个对象。python 不能用任何内置函数,而且速度非常慢。在我们的示例中,我们得到了一个具有 65 列和 1140 行的数据帧,它包含 2016-2019 赛季的足球比赛结果。我们要创建一个新的列来指示某个特定的队是否打过平局。我们可以这样开始:

因为我们的数据框架中包含了英超的每一场比赛,所以我们必须检查我们感兴趣的球队(阿森纳)是否参加过比赛,是否适用,他们是主队还是客队。如你所见,这个循环非常慢,需要 207 秒才能执行。让我们看看如何提高效率。
在第一个示例中,我们循环访问了整个数据帧。iterrows()为每行返回一个序列,因此它以一对索引的形式在数据帧上迭代,而感兴趣的列以序列的形式迭代。这使得它比标准循环更快:

代码运行需要 68 毫秒,比标准循环快 321 倍。但是,许多人建议不要使用它,因为仍然有更快的方法,并且 iterrows() 不保留跨行的数据类型。这意味着,如果在数据帧上使用 iterrow(),则可以更改数据类型,这会导致很多问题。要保留数据类型,还可以使用 itertuples()。我们不会在这里详细讨论,因为我们要关注效率。你可以在这里找到官方文件:
apply 本身并不快,但与数据帧结合使用时具有优势。这取决于应用表达式的内容。如果可以在 Cython 空间中执行,则速度会更快(在这里就是这种情况)。
我们可以将 apply 与 Lambda 函数一起使用。我们要做的就是指定轴。在这种情况下,我们必须使用 axis=1,因为我们要执行一个列操作:

此代码甚至比以前的方法更快,只需要 27 毫秒就能完成。
现在我们可以讨论一个新话题了。我们利用矢量化的优点来创建真正快速的代码。重点是避免像前面的例子 [1] 中那样的 Python 级循环,并使用优化的 C 代码,这个代码使用内存的效率更高。我们只需要稍微修改函数:
现在我们可以用 pandas series 作为输入创建新列:

在这种情况下,我们甚至不需要循环。我们要做的就是调整函数的内容。现在我们可以直接将 pandas series 传递给我们的函数,这会导致巨大的速度增益。
在前面的示例中,我们将 pandas series 传递给了函数。通过添加.values,我们收到一个 Numpy 数组:

Numpy 数组非常快,我们的代码运行时间为 0305 毫秒,比开始使用的标准循环快 71803 倍。
如果您使用 python、pandas 和 Numpy 进行数据分析,那么代码总会有一些改进空间。我们比较了五种不同的方法,在计算的基础上增加了一个新的列到我们的数据框架中。我们注意到在速度方面存在巨大差异:

如果你从这篇文章中选择两条规则,我会很高兴:





